
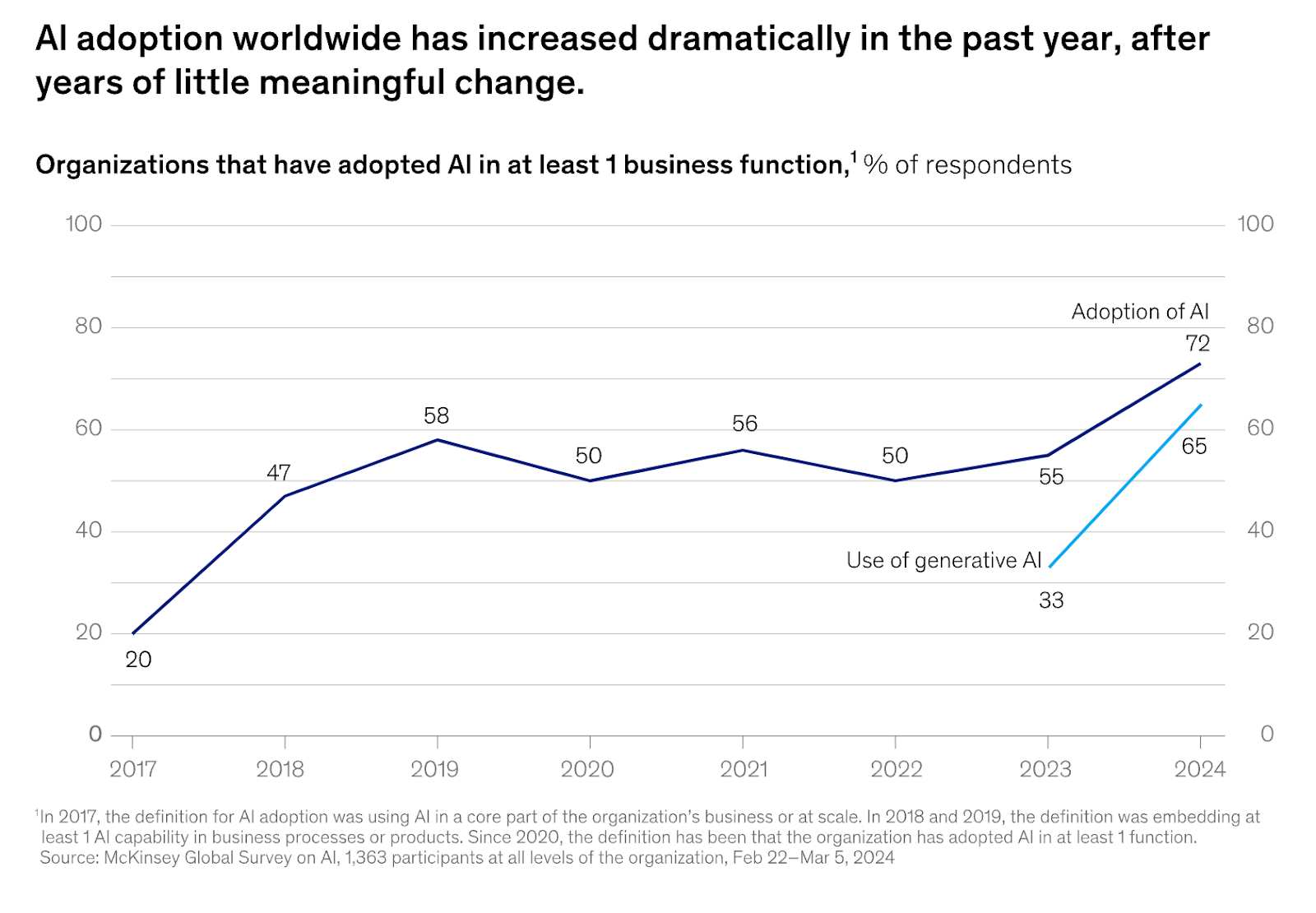
AI adoption has surged dramatically since 2023, after years of little meaningful change. According to Mckinsey’s report “The State of AI in Early 2024”, 72% of companies have integrated AI in at least one business function.
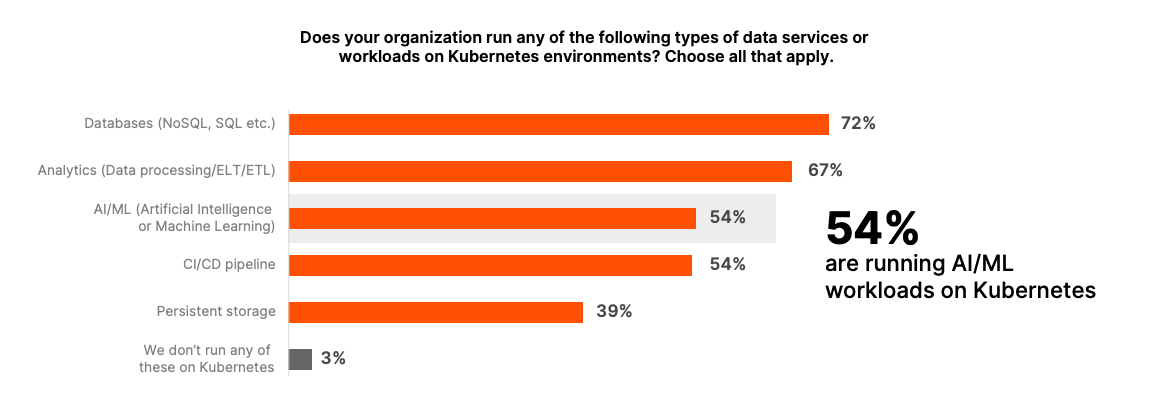
This significant adoption is mirrored in Cloud Native environments, with over 54% of AI workloads now running on Kubernetes, according to “The voice of Kubernetes Experts Report 2024”.
This explosive growth is exciting, but it also emphasizes one very important aspect: we need to re-evaluate how we support these workloads on Kubernetes.
As AI’s complexity increases, it becomes almost like a black box, requiring a deep investigation into all the datasets, metadata, and deployment processes involved. It’s crucial that we understand these fundamentals in order to build platforms that are robust enough to support AI workloads.
When Kubernetes was first introduced, it was not initially designed with AI in mind, given its niche status at the time. However, with the surge in AI adoption, we need to ask ourselves: how much can we stretch Kubernetes to support AI workloads?

A star is born - DRA (Dynamic Resource Allocation)
In response to the requirements imposed by AI, Kubernetes is evolving. Its architecture is adapting and a feature has emerged in the Cloud Native universe: Dynamic Resource Allocation (DRA).
DRA addresses previous limitations by offering flexible and efficient resource allocation strategies, which are essential for supporting complex AI workloads. This feature allows for dynamic and shared usage of resources such as GPUs, optimizing performance without the overhead of static partitioning.
DRA introduced some key concepts including:
- Device Class - Created by a cluster admin, this configuration set makes specific devices, like GPUs, available within a cluster. It allows for device-specific initialization, such as executing commands with root privileges for setup when a device is prepared for use.
- ResourceSlice - A collection of devices for which resources can be allocated. It allows for defining shared capacity that can be utilized by one or more devices on the node, similar to managing memory blocks in a GPU.
- ResourceClaim - Similar to a persistent volume claim, a ResourceClaim can be referenced in a pod, enabling containers within a pod to share the same subset of GPU resources.
To join us in these innovations, consider contributing to the Kubernetes SIGs project and reviewing the associated documentation.
KubeFlow: Democratizing AI Infrastructure
There are several other projects in the Cloud Native ecosystem which are making AI infrastructure more accessible. One of such projects is KubeFlow, a machine learning toolkit that enhances Kubernetes capabilities. KubeFlow addresses critical user demands, such as model registry - which is essential for managing model versions and metadata. This addition eliminates previous challenges in tracking and deploying AI models, streamlining operations for AI engineers and MLOps practitioners.
AI at the Edge: WasmEdge Project
The WasmEdge project, part of the Cloud Native Computing Foundation (CNCF), is advancing AI infrastructure by offering a lightweight and portable AI and LLM (Large Language Model) runtime. It currently supports Rust, and JavaScript support is on the horizon.
WasmEdge allows you to perform operations through its API without worrying about GPU drivers or tensor libraries. By compiling AI applications into Wasm, you can distribute or deploy Wasm binary files using the tools that you’re already familiar with.
Improving observability: OpenTelemetry
Running AI models, especially LLMs, without proper observability is like flying blind. Observability is crucial for monitoring request information, tracking LLM chains, and managing latencies and high cardinality in data.
OpenTelemetry is pioneering the development of standards for AI observability, defining best practices for debugging and evaluating LLM performance, tracking operational costs, and ensuring ethical use of AI.
AI safety and responsible use
The synergies between AI and Cloud Native systems open a new realm of possibilities. Kubernetes offers a scalable, efficient, and resilient platform for AI workloads. On the other hand, AI contributes to the Cloud Native landscape with predictive analysis and generative AI, improving security with vulnerability scanning.
As AI usage continues to grow at the intersection of Cloud Native and Machine Learning, it is crucial for us to focus on responsible use. With AI’s widespread adoption, its pitfalls also become more risky and impactful. The responsibility lies with all of us, especially software builders, to learn how to consume and produce AI responsibly.
One critical consideration for a responsible AI usage is bias. A model is only as good as the data that it has been trained on. And a recent project, “Gender Shades”, has revealed that AI-powered gender classification products perform worse on women and people with dark skin. These results emphasise the need for using diverse datasets for correctly training AI.
Some final words
As the AI landscape continues to expand within Cloud Native environments, now is the time for all of us to leverage its potential. If you’re eager to contribute and engage in discussions, consider joining these groups:
- Join the CNCF Working Group AI
- Contribute to the Cloud Native playground for AI workloads on GitHub
For more details, you can visit the full talk at ContainerDays Conference 2024: Why we need to think about AI and Cloud Native NOW.

